Synthetic Data Generation Market Size, Share & Industry Analysis, By Data Type (Text Data, Image & Video Data, Tabular Data, and Others), By Application (Test Data Management, AI Training & Development, Enterprise Data Sharing, and Data Analytics & Visualization), By Industry (Healthcare, Manufacturing, Media and Entertainment, Automotive, BFSI, Retail & E-commerce, IT & Telecommunication, and Others), and Regional Forecast, 2026-2034
KEY MARKET INSIGHTS
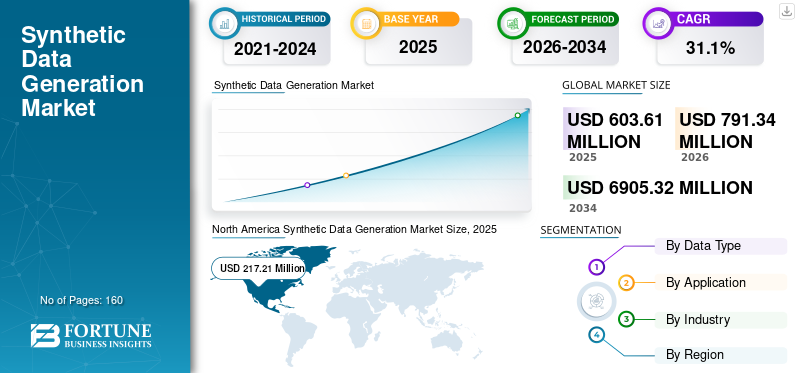
The global synthetic data generation market size was valued at USD 603.61 million in 2025. The market is projected to grow from USD 791.34 million in 2026 to USD 6905.32 million by 2034, exhibiting a CAGR of 31.10% during the forecast period. North America dominated the synthetic data generation market with a market share of 35.99% in 2025.
Synthetic data generation is a process through which data is created algorithmically or artificially and isn’t based on real-world phenomena. Synthetic data is a distorted version of the original data that can be created through statistical modeling and simulation processes using proper tools and cost-effective data augmentation techniques.
According to industry experts, by 2024, almost 60% of data used to develop AI and analytics projects will be synthetically generated. This data can be generated using various methods, including simulations, statistical sampling, and Generative Adversarial Networks (GAN) and is used as a substitute test dataset for production or operational data to validate mathematical models and train machine learning models. The synthetic data generation process is helpful when collecting real-world data is challenging or impractical.
Download Free sample to learn more about this report.
Download Free sample to learn more about this report.
LATEST TRENDS
Surge in Deployment of Large Language Models (LLM) to Augment the Market Growth
Large Language Models (LLM) are learning algorithms that help translate, generate, and predict text and other types of content based on large datasets and the continuous development of websites and various solutions that use language models. Generative Pre-trained Transformer (GPT) is a language model that generates text data using GPT-1, GPT-2, and GPT-3 models. GPT-3 is the most complex model and has reached 175 million machine learning parameters to create a large dataset of conversational data.
The continuous development of websites and other database solutions leverages the demand for language models across various industries, which include retail, healthcare, tech, and others. These language models are used by different end-users for text generation, image annotation, fraud detection, conversational AI, and code generation.
Hence, the rise in deployment of Large Language Models (LLM) is anticipated to drive market growth during the forecast period.
SYNTHETIC DATA GENERATION MARKET GROWTH FACTORS
Growing Demand for Data Privacy and Security to Fuel Market Growth
Real-world data cannot be accessed due to privacy concerns or compliance risks along with the regulations imposed by General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), and Health Insurance Portability and Accountability Act (HIPAA). The rise in privacy risks for collecting real-world datasets generates demand for synthetic data, a realistic version of the real data set with similar statistical properties. This synthesized data can be used as an alternative to real data and offers several advantages regarding privacy, scalability, and diversity.
For instance, in April 2023, Betterdata, a Singapore-based startup declared to use synthetic data that has similar characteristics and structure to real-world dataset without disclosing sensitive or private information of an individual to secure confidential data and enhance machine learning models.
RESTRAINING FACTORS
Lack of Data Accuracy and Realism Hinders Market Growth
Synthetic data generation creates virtual replicas of datasets that can be tested and shared with users. Moreover, this process faces difficulty capturing the minute details of real-world images and specialized models.
As synthetic data depends on real-world data and changes due to innovations and developments, keeping the synthetic dataset constant over time is challenging. Hence, organizations should regularly ensure the synthetic data's accuracy and reliability.
This factor hampers the synthetic data's accuracy and realism, significantly hindering the synthetic data generation market growth.
SEGMENTATION ANALYSIS
By Data Type Analysis
Tabular Data Exhibits Prominent CAGR by Addressing Privacy Concerns with Artificial Data
Based on data type, the market is segmented into text data, image & video data, tabular data, and others. Recently, companies are facing challenges in collecting real-life data due to privacy concerns. These challenges lead to generating artificial data that mimics real world data, which can be stored in structured tabular format. This boosts the demand for tabular data, which is expected to grow with a prominent CAGR during the forecast period. Synthetic tabular data can be created using Generative Adversarial Network (GAN) to help businesses enhance operational data privacy and security.
According to research analysts, using synthetic tabular data to train Artificial Intelligence (AI) models will grow approximately three times faster than real structured data by 2030.
Furthermore, the text data segment is projected to grow with the largest market share due to increasing usage of natural language generation systems with new machine learning models.
By Application Analysis
Increasing Need of Test Data Management by Test Managers Contributing to Segmental Growth
Based on application, the market is divided into test data management, AI training & development, enterprise data sharing, and data analytics & visualization. The test data management segment holds the largest market share due to increasing need of the smallest set of data by the test data manager for data testing & data masking. It also aims to avoid legal problems associated with GDPR.
The enterprise data sharing segment grows steadily as enterprises are facing difficulty during cross-border data sharing.
By Industry Analysis
To know how our report can help streamline your business, Speak to Analyst
BFSI Industry Dominates Owing to Rise in Number of Fraud Cases and Usage of Algorithmic Trading
On the basis of industry, the market is divided into healthcare, manufacturing, media & entertainment, automotive, BFSI, retail & e-commerce, IT & telecommunication, and others. Increasing usage of synthetic data across BFSI industry helps enhance the fraud detection technique, risk analysis, and algorithmic trading to validate complex data structures. Thus, the BFSI segment leads to enhance the usage of synthetic data to deliver data-driven banking experiences to global customers. The healthcare segment is expected to lead the market, contributing 16% globally in 2026.
Similarly, the healthcare segment leads with the second-position in the market as increasing usage of synthetic data in the healthcare industry helps to perform cl inical trials, scientific research, generate medical images, and predict rare diseases. Thus, the healthcare segment grows with highest CAGR during the forecast period.
REGIONAL ANALYSIS
North America Synthetic Data Generation Market Size, 2025 (USD Million)
To get more information on the regional analysis of this market, Download Free sample
The global market scope is classified across five regions, North America, Europe, Asia Pacific, the Middle East & Africa, and South America.
North America
North America dominated the market with a valuation of USD 217.21 billion in 2025 and USD 284.77 billion in 2026. North America holds the largest synthetic data generation market share, owing to the presence of multiple market players. The rising number of AI startups, research institutes, and high-tech companies generates demand for high-quality synthetic data to conduct research and experiments. This factor fuels the market growth across the region.
Asia Pacific
Asia Pacific is expected to grow with the highest CAGR during the forecast period. It is due to the rising penetration of advanced technologies such as AI/ML and the growing adoption of cloud-based services among different industries to build secure business infrastructure. Increasing investment in generative AI and the rising focus of companies on AI technology are anticipated to propel the demand for synthetic data generation processes in Asia Pacific during the forecast period.
Europe
Europe is expected to grow with a significant CAGR during the forecast period due to the presence of multiple synthetic data vendors and tremendous growth in funding for structured synthetic data vendors to bring developments in the in-house synthetic data capabilities of organizations. This factor is projected to propel the market growth during the forecast period.
To know how our report can help streamline your business, Speak to Analyst
Middle East & Africa and South America
The Middle East & Africa and South America are growing due to increasing digital transformation initiatives across BFSI, healthcare, automotive, and media & entertainment. Integrating artificial intelligence and machine learning technologies with finance and the automotive industry to generate reliable synthetic data fuels the market growth of synthetic data generation across both regions.
KEY INDUSTRY PLAYERS
Key Players Focus on Generating Synthetic Data to Strengthen their Position
Synthetic data generation companies include Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc., and K2view Ltd., among others. Increasing investments in generation of synthetic data for different industry verticals are helping key players maintain their competitive edge. These companies also engage in strategic partnerships, acquisitions, and collaborations to expand their business and distribution network and maintain market growth.
List of Key Companies Profiled in Synthetic Data Generation Market:
- Datagen (U.S.)
- MOSTLY AI (Austria)
- TonicAI, Inc. (U.S.)
- Synthesis AI (U.S.)
- GenRocket, Inc. (U.S.)
- Gretel Labs, Inc. (U.S.)
- K2view Ltd. (Israel)
- Hazy Limited. (U.K.)
- Replica Analytics Ltd. (Canada)
- YData Labs Inc. (U.S.)
- Sogeti (France)
KEY INDUSTRY DEVELOPMENTS:
- June 2023: Seeing Machine Limited collaborated with Devant AB, a human-centric synthetic data provider, to enhance transport safety by understanding distracted driver behavior. This partnership led to integrating Seeing Machine's new vehicle cabin with Devant’s 3D human animation and computer-generated humans to bring development in in-cabin sensing technology.
- May 2023: Synthesis AI launched a new enterprise synthetic dataset on the Snowflake marketplace, where their customers can access readily available Synthesis AI’s synthetic human faces to develop visual data for the computer vision model without compromising Synthesis AI’s consumer privacy.
- December 2021: Gretel.ai partnered with Illumina, Inc. to deliver synthetic data for research in genomics and other related fields, including forensic biology, biotechnology, and biological systematics to enhance the development of precision medicine.
- May 2021: Parallel Domain, a synthetic data generation platform provider, launched the industry-first public synthetic data visualizer, which helps the industry engineers directly interact with the fully-labeled synthetic camera and LiDAR datasets to test, deploy, and train machine learning solutions.
- April 2021: Unity Software Inc. launched synthetic image datasets to develop computer vision artificial intelligence models that can be used at lower costs in Architecture, Engineering, and Construction (AEC) industries.
REPORT COVERAGE
The report provides a detailed analysis of the market and focuses on key aspects such as leading companies, product/service types, and leading applications of the product. Moreover, the report offers insights into the market trends and highlights key synthetic data generation industry developments. In addition to the factors above, the report encompasses several factors that have contributed to the growth of the market in recent years.
Request for Customization to gain extensive market insights.
Report Scope & Segmentation
|
ATTRIBUTE |
DETAILS |
|
Study Period |
2021-2034 |
|
Base Year |
2025 |
|
Estimated Year |
2026 |
|
Forecast Period |
2026-2034 |
|
Historical Period |
2021-2024 |
|
Growth Rate |
CAGR of 31.1% from 2026 to 2034 |
|
Unit |
Value (USD Million) |
|
Segmentation |
By Data Type, Application, Industry, and Region |
|
By Data Type |
|
|
By Application |
|
|
By Industry |
|
|
By Region |
|
Frequently Asked Questions
The market is projected to reach USD 6905.32 million by 2034.
In 2025, the market was valued at USD 603.61 million.
The market is projected to grow at a CAGR of 31.1% during the forecast period.
The test data segment is expected to lead the market.
Growing demand for data privacy and security to fuel market growth.
Datagen, MOSTLY AI, TonicAI, Inc., Synthesis AI, GenRocket, Inc., Gretel Labs, Inc., K2view Ltd., Sogeti, and Hazy Limited are the top players in the market.
North America is expected to hold the highest market share.
The healthcare segment is expected to grow with a remarkable CAGR during the forecast period.



- 2021-2034
- 2025
- 2021-2024
- 160
Get 20% Free Customization
Expand Regional and Country Coverage, Segments Analysis, Company Profiles, Competitive Benchmarking, and End-user Insights.
Related Reports
-
US +1 833 909 2966 ( Toll Free )
-
Get In Touch With Us